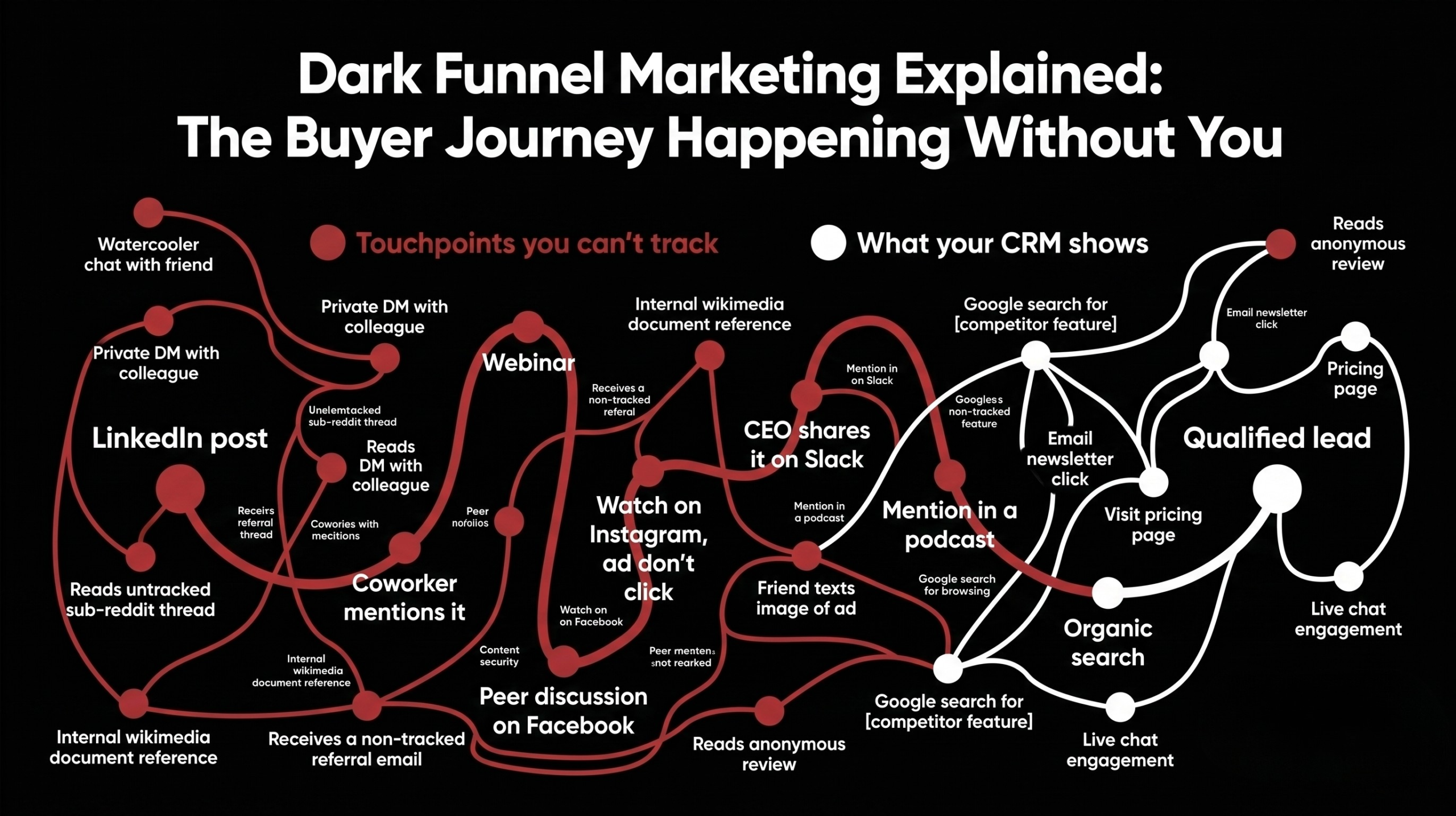
In May 2024, roughly 2,596 internal Google documents detailing 14,014 attributes from the Content Warehouse API leaked to the public. The documentation directly contradicted years of public statements from Google representatives on topics including domain authority, click-based ranking, and the existence of a sandbox for new sites. Most SEO commentary treated the leak as gossip. The more useful question is what it actually revealed about how rankings are constructed, and which of your assumptions need to be retired. The reading below is the same operating thesis our engineering-led SEO services have been running on through 2025 and 2026.
This article breaks down the consequential findings, the ranking systems they exposed, and the specific practitioner adjustments the documentation justifies.
What the Leak Actually Was
The leak was not the algorithm source code. It was internal API documentation describing the attributes, modules, and data structures Google’s search infrastructure uses to store and retrieve information about pages, sites, and users.
The documents covered systems with names like Navboost, NSR (Normalized Site Rank), Mustang, Tangram, and Glue. They confirmed the existence of attributes Google had publicly denied using, exposed scoring mechanics for trust and authority, and described how various ranking layers interact.
Critically, the documentation reveals what Google measures, not how each signal is weighted. Treat the leak as a map of the inputs, not a formula for the output.
The Site Authority Signal Google Denied Existed
Google representatives repeatedly stated on record that “domain authority” was not a metric Google used. The leaked documentation contains an attribute called siteAuthority, a quality score computed at the site level and fed into the Q* ranking system.
This matters operationally. Site-level authority compounds across pages: a strong domain elevates every URL on it, while a weak domain handicaps even well-optimized individual pages. The specific E-E-A-T artefacts that feed site-level authority signals – author bios, citations, entity associations are detailed in our E-E-A-T signals guide.
- New content on established, trusted domains starts with an advantage over identical content on weaker domains.
- Site-level quality problems, thin pages, low engagement, spam signals, drag down pages that would otherwise rank.
- Domain consolidation strategies (moving multiple weaker properties under one strong domain) have algorithmic justification, not just brand logic.
The third-party “Domain Authority” metrics from Moz, Ahrefs, and Semrush were never the actual Google signal. The leak confirmed Google maintains its own internal version.
The Sandbox is Real
For two decades, Google denied the existence of a sandbox penalizing new websites. The leaked documentation contains a hostAge attribute explicitly used to “sandbox fresh spam in serving time.”
The mechanism isn’t a punishment, it’s a trust-building period during which new domains are evaluated more cautiously before being permitted to rank for competitive queries. Practical consequences:
- New domains targeting competitive commercial queries should expect 6-12 months of suppressed visibility regardless of content quality or backlinks.
- Aged domain acquisitions retain some trust signals, which explains the persistent market for expired domains with clean histories.
- Brand-building activities that generate searches for your domain name appear to accelerate trust accumulation.
This doesn’t mean you wait passively. It means you set realistic ranking timelines and prioritize long-tail and branded queries while authority accumulates.
Author Entities Get Tracked at the Person Level
The documentation includes an isAuthor attribute and mechanisms for associating content with author entities maintained separately from the publishing domain.Google appears to track authors as first-class entities with their own authority signals. The underlying mechanic – how Google maps people, brands, and topics as nodes in a knowledge graph – is documented in our Entity SEO primer.
This validates the operational push toward bylined content with rich author bios linked to verifiable external profiles. The author entity carries weight across publications:
- Author schema markup with sameAs properties pointing to LinkedIn, academic profiles, and other authoritative sources
- Consistent attribution across guest posts, podcast appearances, and conference talks
- Topical specialization rather than generalist publishing, author authority appears to compound within specific entity clusters.
- Cross-publication presence that builds the author’s identity independently of any single domain
If your YMYL content (health, finance, legal) is published anonymously or under generic editorial bylines, the leak suggests you’re leaving authority signals on the table.
Twiddlers: The Re-Ranking Layer
The documentation extensively describes “twiddlers” re-ranking functions that adjust results after the initial ranking pass. Twiddlers can boost or demote pages based on freshness, diversity requirements, query intent, or topic-specific quality signals.
This explains why pages can rank in position 4 for months, then suddenly jump to position 1 or drop to position 15 without any change to the page itself. A twiddler firing differently, perhaps because the query was reclassified, or a freshness boost was activated, produces volatility that looks unexplained at the page level. The user-behaviour signals these re-rankers consume – pogo-sticking, dwell time, return-to-SERP – are the same ones documented in our SXO breakdown.
You should track ranking changes against query-level patterns rather than assuming every fluctuation reflects a page issue. SERP feature changes, query intent shifts, and seasonal twiddlers explain most movement that lacks an on-page cause.
Chrome Data Confirmed as a Ranking Input
he leaked documentation references Chrome browser data being used in ranking, contradicting prior denials. Brands that want their site audited against the actual confirmed ranking factors rather than the public guidance can engage our SEO experts in Kolkata for a leak-informed technical and content audit.
The practical implication: your site’s behaviour in actual Chrome installations, load performance, error rates, and user navigation patterns feed back into how Google evaluates the site. This isn’t just Core Web Vitals from CrUX. It appears broader, including patterns of how users move through your site after arriving from any source, not only from search.
Performance work, accessibility improvements, and reducing user-facing errors have ranking value beyond their direct UX benefit.
The leak doesn’t hand you a new playbook, it confirms that the playbook serious practitioners have been running was directionally correct. Prioritize site-level quality over individual page tactics, plan for sandbox-style suppression on new domains, invest in author entities for YMYL content, treat ranking volatility as a twiddler signal rather than a page problem, and recognize that user behaviour in Chrome feeds back into rankings. The teams that ignored Google’s public denials and built strategies around behavioural logic have been right. The documentation now lets you make that case internally with evidence.